
[B! Stable Diffusion] Stable Diffusionのimg2img機能でAI画伯で絵を変化させてみる 親子ボードゲームで楽しく学ぶ。
Stable Diffusion WebUI Online. Access Stable Diffusion's powerful AI image generation capabilities through this free online web interface. Our user-friendly txt2img, img2img, and inpaint tools allow you to easily create, modify, and edit images with natural language text prompts. No installation or setup is required - simply go to our.

How to cartoonize photo with Stable Diffusion Stable Diffusion Art
Part 2: Using IMG2IMG in the Stable Diffusion Web UI . In Part 1 of this tutorial series, we reviewed the controls and work areas in the Txt2img section of Automatic1111's Web UI. If you haven't read that yet, I suggest you do so before moving onto this part. Now it's time to examine the controls and parameters related to Img2img generation.

Img2img Stable Diffusion 2.1 r/StableDiffusion
Once you've uploaded your image to the img2img tab we need to select a checkpoint and make a few changes to the settings. First of all you want to select your Stable Diffusion checkpoint, also known as a model. Here I will be using the revAnimated model. It's good for creating fantasy, anime and semi-realistic images.

Mastering Stable Diffusion with img2img A Comprehensive Guide
In Conclusion. With the modified handler python file and the Stable Diffusion img2img API, you can now take advantage of reference images to create customized and context-aware image generation apps. You can experiment further and update the config object to easily expose other Stable Diffusion APIs. Happy diffusing.
The Illustrated Stable Diffusion Jay Alammar Visualizing machine learning one concept at a time.
img2img settings. Set image width and height to 512.. Set sampling steps to 20 and sampling method to DPM++ 2M Karras.. Set the batch size to 4 so that you can cherry-pick the best one.. Set seed to -1 (random).. The two parameters you want to play with are the CFG scale and denoising strength.In the beginning, you can set the CFG scale to 11 and denoising strength to 0.75.

The power of Stable Diffusion Img2img Stable Diffusion Know Your Meme
stability-ai / stable-diffusion-img2img. Generate a new image from an input image with Stable Diffusion Public; 891.6K runs GitHub License Playground API Examples README Versions. Examples. View more examples . Run time and cost. This model runs on Nvidia A100 (40GB) GPU hardware..

Stable Diffusion img2img & txt2img Using AMD on Windows YouTube
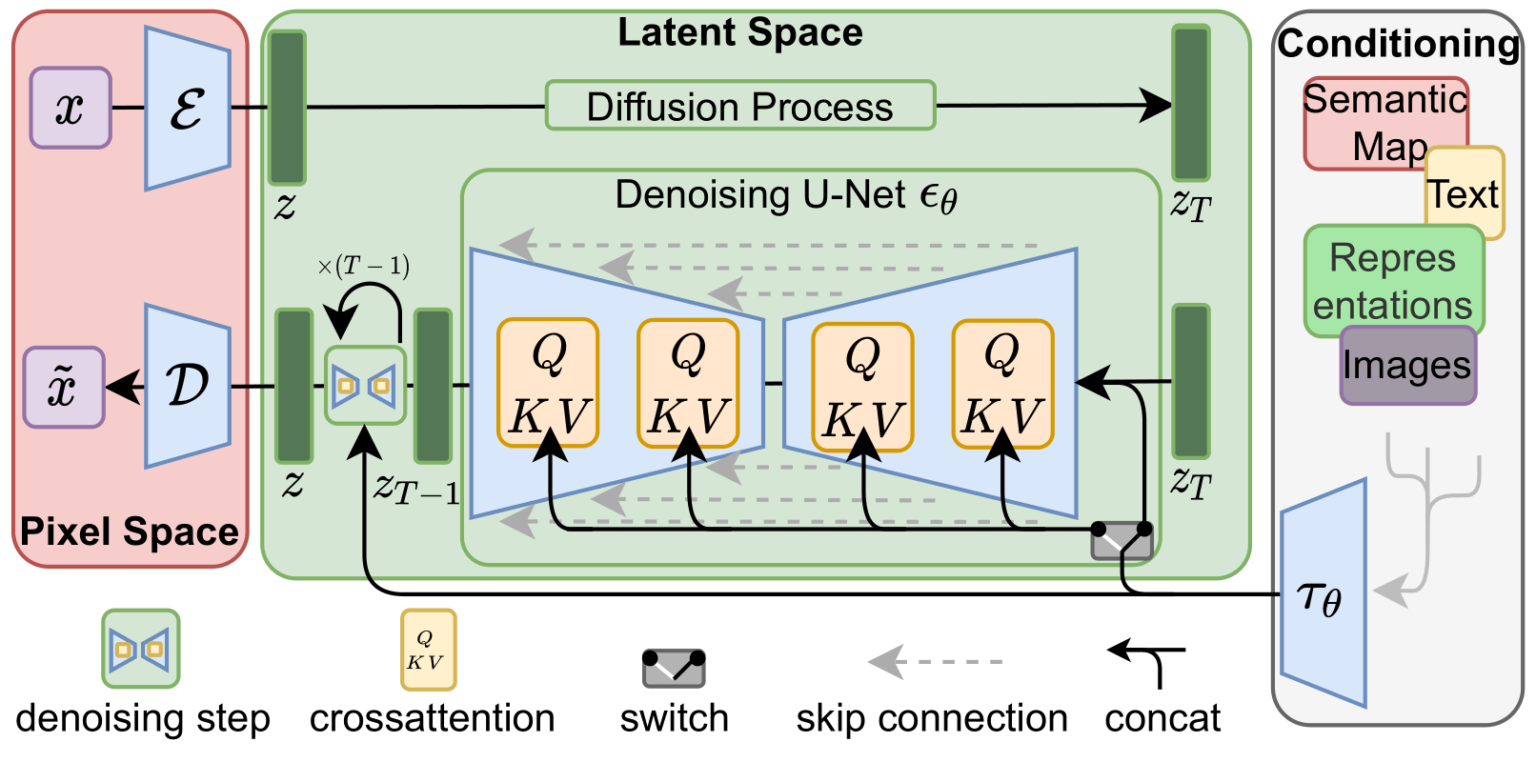
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from CompVis, Stability AI and LAION. It's trained on 512x512 images from a subset of the LAION-5B database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the.

Stable Diffusion AI Model Can Turn Video Game Characters Into Photorealistic Humans TechEBlog
The Stable Diffusion model can also be applied to image-to-image generation by passing a text prompt and an initial image to condition the generation of new images. The StableDiffusionImg2ImgPipeline uses the diffusion-denoising mechanism proposed in SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations by Chenlin.

如何利用Stable Diffusion img2img功能给模特换装教程 知乎
Running the Diffusion Process. With your images prepared and settings configured, it's time to run the stable diffusion process using Img2Img. Here's a step-by-step guide: Load your images: Import your input images into the Img2Img model, ensuring they're properly preprocessed and compatible with the model architecture.
stabilityai/stablediffusionimg2img API reference
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. It is considered to be a part of the ongoing AI spring . It is primarily used to generate detailed images conditioned on text descriptions, though it can also be applied to other tasks such as inpainting , outpainting, and generating image-to-image translations guided by a text prompt . [3]

It's how SD Upscale supposed to works? (img2img) · Issue 878 · AUTOMATIC1111/stablediffusion
Stable Diffusion v2. Stable Diffusion v2 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet and OpenCLIP ViT-H/14 text encoder for the diffusion model. The SD 2-v model produces 768x768 px outputs.

stable diffusion img2img walkthrough paint an bussin watercolor in minutes (no cap) Krita
With your sketch in place, it's time to employ the Img2Img methodology. Follow these steps: From the Stable Diffusion checkpoint selection, choose v1-5-pruned-emaonly.ckpt. Formulate a descriptive prompt for your image, such as "a photo of a realistic banana with water droplets and dramatic lighting.". Enter the prompt into the text box.

img2img full resolution · Discussion 522 · hlky/stablediffusionwebui · GitHub
Discussion. --UPDATE V4 OUT NOW-- Img2Img Collab Guide (Stable Diffusion) - Download the weights here! Click on stable-diffusion-v1-4-original, sign up/sign in if prompted, click Files, and click on the .ckpt file to download it! https://huggingface.co/CompVis. - Place weights inside your BASE google drive "My Drive".

Just installed Stable Diffusion, it's insane how well img2img works. StableDiffusion
You are welcome to try our free online Stable Diffusion based image generator at https://www.aiimagegenerator.org It supports img2img generation, including sketching of the initial image :) Pop ups everywhere. Don't click that link. Cool site.

How to Use Img2Img Stable Diffusion YouTube
Upload the original image to img2img and enter prompts, and click Generate on Cloud. Select corresponding Inference Job ID, the generated image will present on the right Output session. Sketch label. Start Stable Diffusion WebUI with '--gradio-img2img-tool color-sketch' on the command line,upload the whiteboard background image to the.

Stable Diffusion Webui
Popular models. The most popular image-to-image models are Stable Diffusion v1.5, Stable Diffusion XL (SDXL), and Kandinsky 2.2.The results from the Stable Diffusion and Kandinsky models vary due to their architecture differences and training process; you can generally expect SDXL to produce higher quality images than Stable Diffusion v1.5.
